인공지능 학습용 데이터 구축, 고서 한자 OCR 길 열어
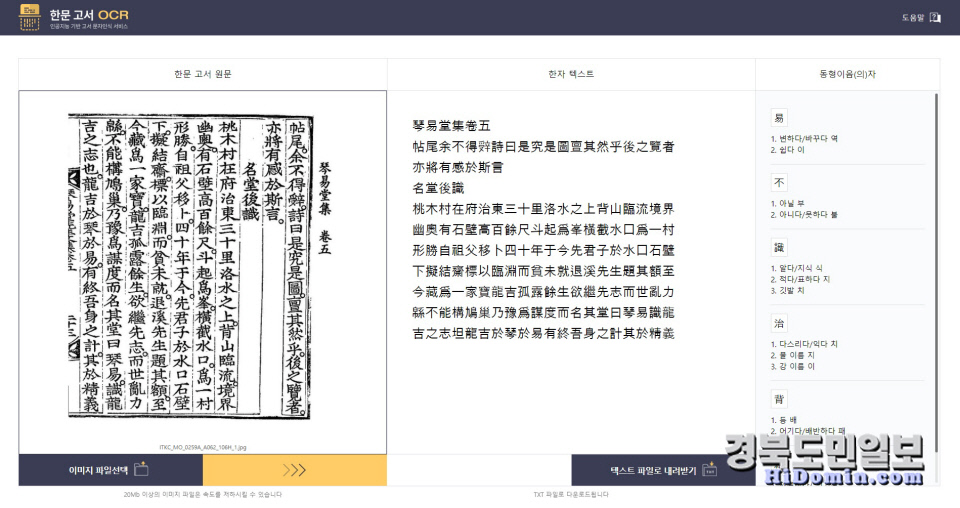
기존 문자인식 프로그램으로는 고도서의 한자 인식에 한계가 많은 실정이다 이에 한국국학진흥원은 고서 속의 한자를 자동 인식할 수 있는 시스템 개발을 진행해 1차년도 사업을 완료했다.
유교책판의 활자를 영인한 고서의 한자 인식률 70%를 목표로 시작했던 1차 사업은 현재 약 80%의 정확도로 문자를 인식하는 수준에 이르렀고 이후 지속적 개발을 통해 정확도를 올릴 예정이다. 이 결과는 현재 최종 품질 검증을 거쳐 AI-Hub를 통해 공개될 예정이다.
유교책판의 활자를 찍어낸 문집 등의 고서는 전통 기록유산 중에서 가장 많은 양을 차지하고 있다. 고서에 대한 접근성을 높이는 것은 한국 전통 인문학의 발전을 앞당기고 전통문화 기반의 새로운 콘텐츠 제작의 가능성을 열어준다.
이를 위해 가장 중요한 첫걸음은 책으로만 남아 있던 고서 내용을 디지털 문자로 치환함으로써 검색성과 활용도를 높이는 일이다.
현재 한글 및 영문, 기타 다양한 언어 영역에서 광학문자인식(OCR) 시스템이 폭넓게 활용되고 있다. 따라서 한국국학진흥원은 광학문자인식 인공지능 모델 개발 전문업체인 ㈜누리IDT 및 ㈜NHN다이퀘스트 등의 기술력을 적용해 한자를 자동으로 인식하기 위한 OCR 시스템 개발에 착수했다.
이번 ‘한자 인식 OCR 인공지능 모델 개발’은 인공지능(AI)이 가진 딥-러닝 기술이 적극 차용됐다. 이번 1년차 사업을 통해 글자수 기준 1000만자의 이미지를 입력하고 이를 인공지능이 지속적으로 학습할 수 있도록 했다.
고해상도의 이미지인 경우 80%의 정확도를 보여주고 있으며 향후 지속적인 사업을 통해 더 많은 글자 이미지를 입력해 인공지능 학습이 이뤄질 수 있게 하면 인식률은 더 높아질 것으로 기대하고 있다.
특히 이 사업이 본 궤도에 오르면 일반 사용자들이 유적지 등을 방문했을 때 한자로 기록된 현판이나 문서들을 이미지로 촬영해 한자의 뜻과 의미를 확인할 수 있게 될 것이며 또 한자 텍스트를 기반으로 개발 중인 자동 번역 시스템과 연계할 때 한국 고전 번역에 획기적인 속도를 기대할 수 있다.
한국국학진흥원 정종섭 원장은 “산적해 있는 고서들을 활용하기 위한 첫 단계가 디지털화 작업인데 이번 1년차 사업만으로도 디지털화 속도가 몇 배 이상 빨라졌다”며 “향후 이미지 인식률을 높일 수 있는 사업을 계속 추진해나갈 것이며 이 결과물이 일반인들이 실생활에서 활용할 수 있는 서비스까지 이어질 수 있도록 노력하겠다”고 말했다.
저작권자 © 경북도민일보 무단전재 및 재배포 금지
<경북도민일보는 한국언론진흥재단의 디지털 뉴스콘텐츠 이용규칙에 따른 저작권을 행사합니다 >
▶ 디지털 뉴스콘텐츠 이용규칙 보기
▶ 디지털 뉴스콘텐츠 이용규칙 보기

http://blog.daum.net/macmaca/3127